This tutorial is meant for executives or data scientists who want to see if
Wendelin is useful for them. Readers should have experience with python.
There is no discussion of what goes on "under the hood" of Wendelin.
After completing the tutorial, the reader should understand:
- what out-of-core analysis is
- how to manipulate ZBigArrays
- that analysis with Wendelin is quite similar to any kind of out-of-core analysis
- that Wendelin/ERP5 is easily extensible
- how to perform out of core machine learning with Wendelin
Install Wendelin Standalone
(Coming Soon) Get A Wendelin VM - Run Locally
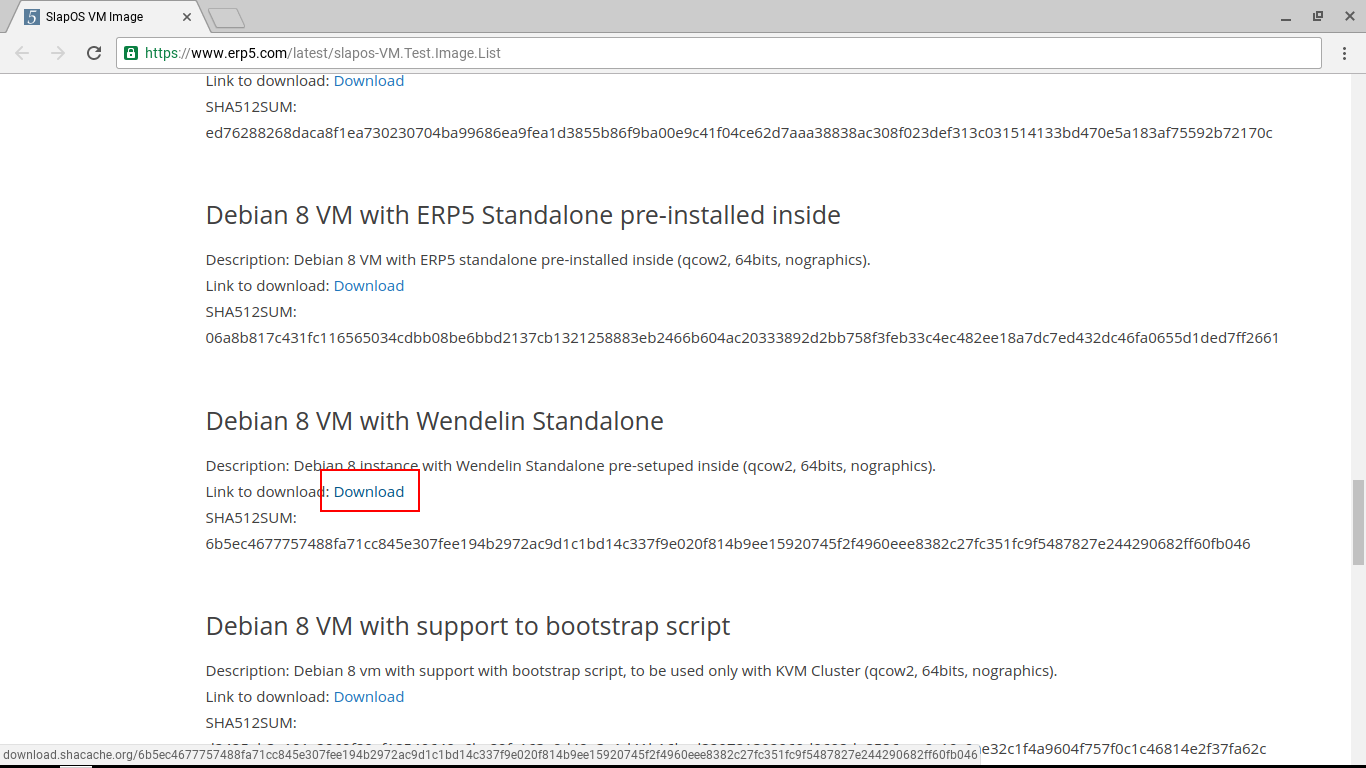
(Coming Soon) Get A Wendelin VM - Run On Cloud
- VIFIB offers affordable, easy-to-use cloud services
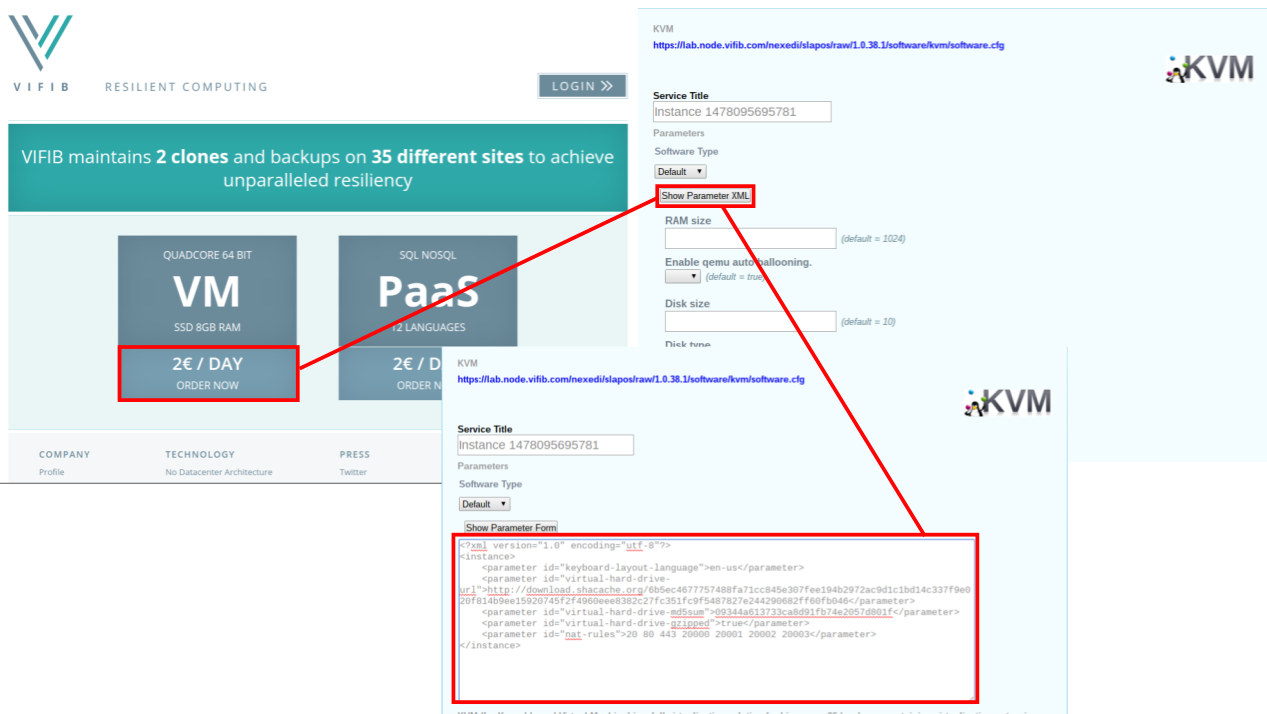
- Order a KVM on the front page and follow the instructions until you reach a page with a request button
- After pressing the request button, you will be taken to a management screen
- On the management screen, click "Show Parameter XML"
- Copy and paste these parameters into the resulting text box
- Click "Update XML"
(Coming Soon) Get A Wendelin VM - Run On Cloud
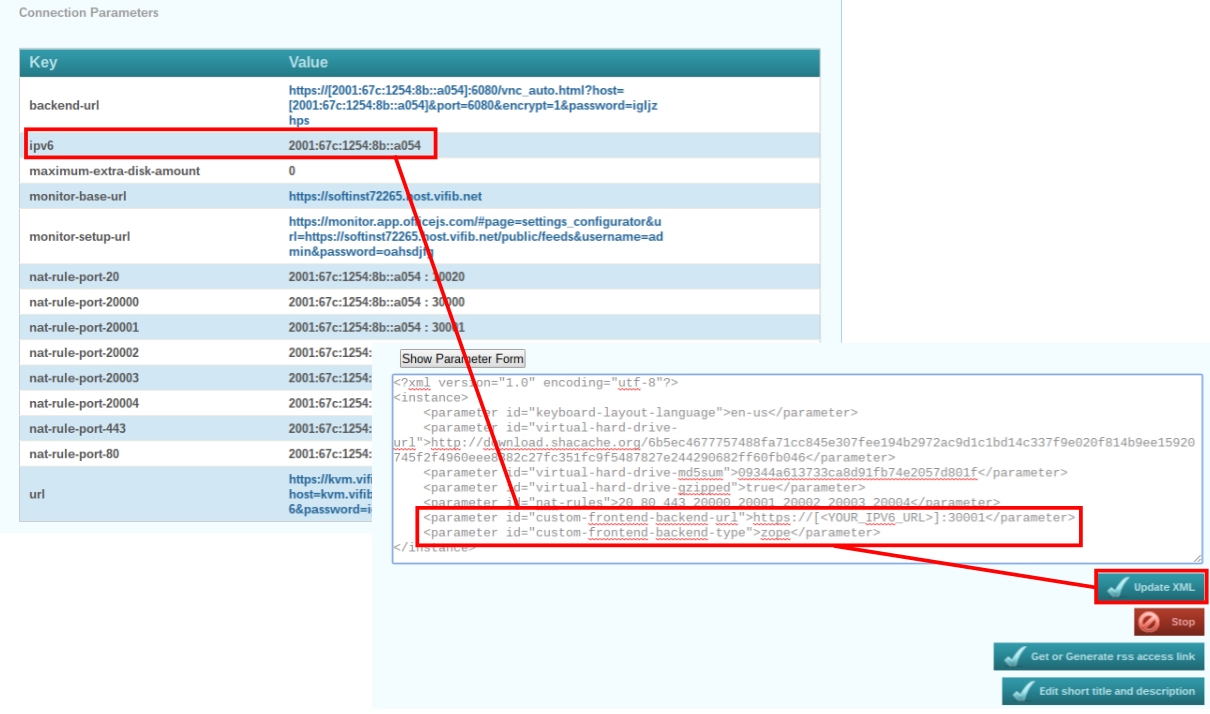
- After a few moments, refresh to see an IPv6 address listed under connection parameters
- Then add these two lines to your parameter XML
- Substitute YOUR_IPV6_URL with the actual IPv6 address, and update the parameters
Welcome to Wendelin
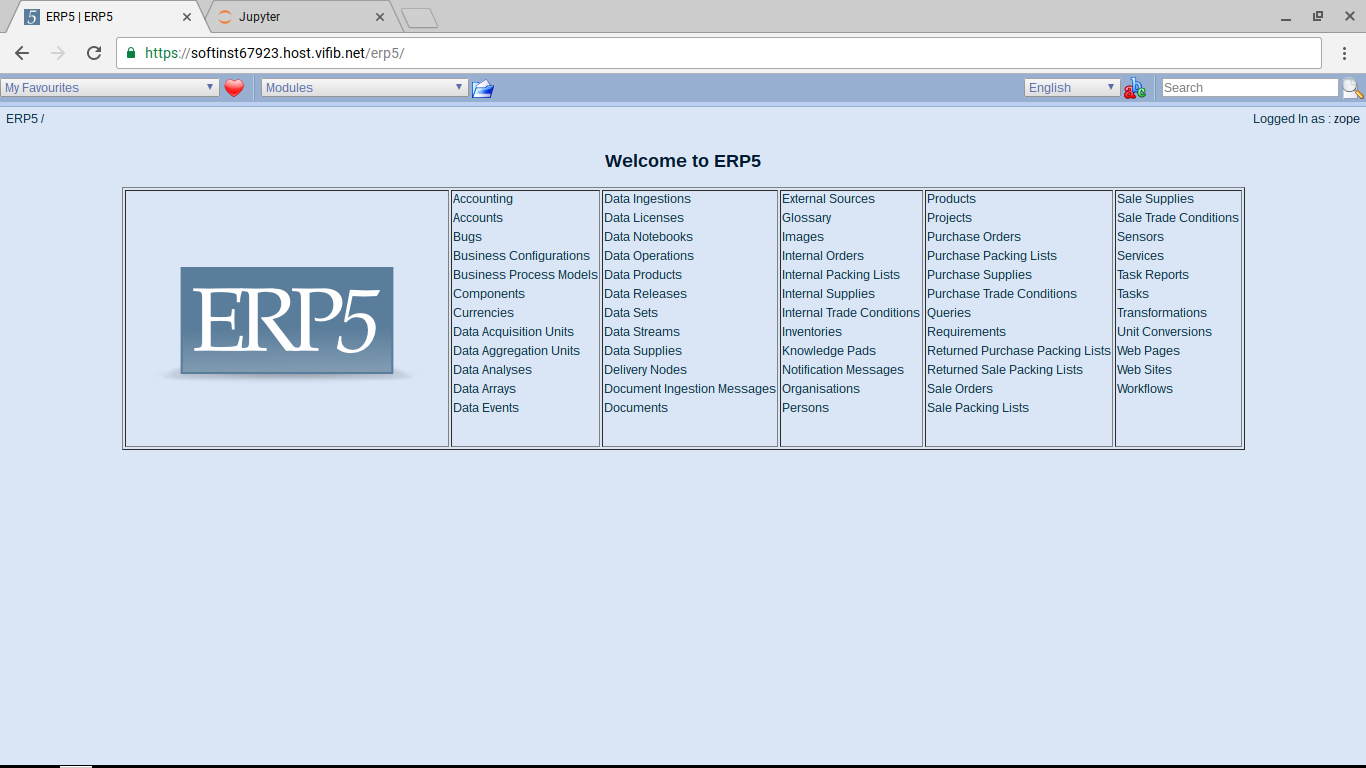
- Navigate to the IP address given to you by SlapOS if running on the cloud or to localhost if running locally
- Port 2151 hosts the ERP5 instance where we will install Wendelin shortly
- Port 8888 hosts the Jupyter instance, where we will spend most of our time
Install Wendelin
- Navigate to
/erp5 on port 2151 and from the My Favourites menu, select Check Site Consistency and then Fix Site Configuration
- Again from the My Favourites menu, select Configure Your Site and choose the Wendelin Configurator
- Follow the instructions on screen until your Wendelin instance is available
Jupyter - ERP5 Kernel
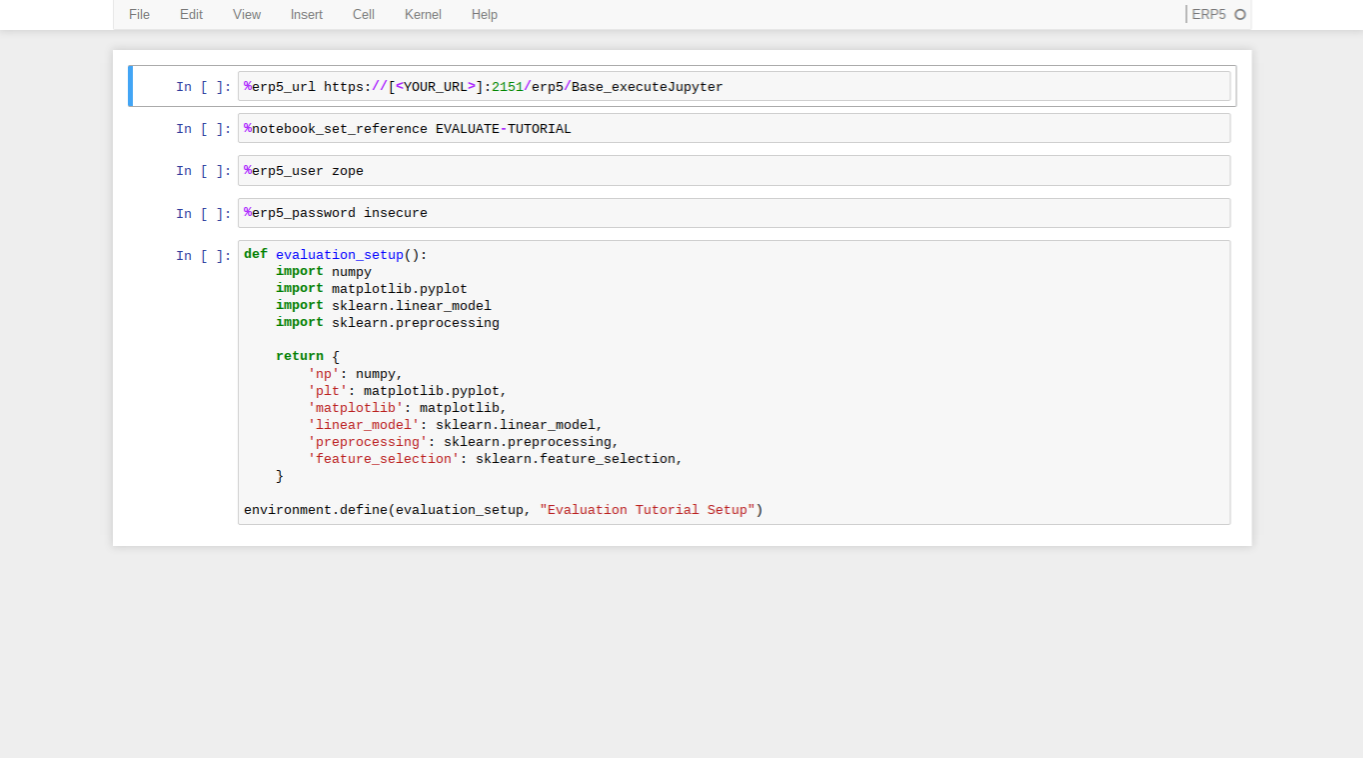
- On the Jupyter tab, create a new ERP5 notebook
- Wendelin uses a custom Jupyter kernel that allows direct access to ERP5
- Connecting to it requires some magics, but the boilerplate comes filled in for this tutorial
- In addition, some datasets are preloaded, you can find them in the ERP5 Data Array Module
- The ERP5 Kernel gives you direct access to some ERP5 objects from Jupyter
- To access an object with ID
foo in the Bar Module, write context.bar_module['foo']
Notebook State
- ERP5 creates a Data Notebook with the reference you provided that pickles and maintains all of the variables you define in your notebook so they are available between cells
- Modules, classes and functions cannot be easily pickled, so they must be exported with setup functions which are automatically run before every cell
- In the screenshot above,
evaluation_setup is the setup function which we export with environment.define
- If the Data Notebook you are connected to gets corrupted, it can lead to errors in Jupyter. In these situations, change the reference you provided and rerun the cell
- You can use
environment.undefine('label given to function') to unload setup functions: useful if one contains an error
Data Arrays, ZBigArrays, ndarrays, views
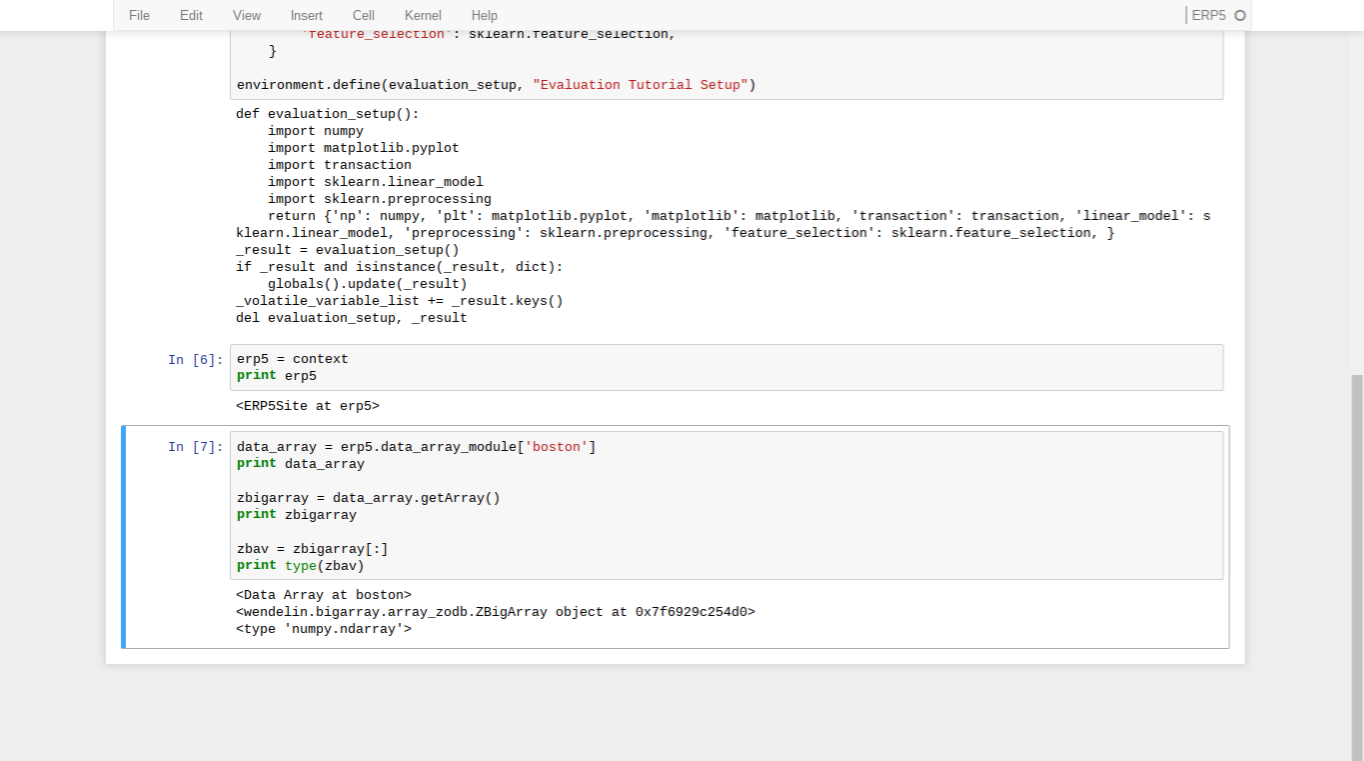
- A Data Array is an ERP5 object that holds a ZBigArray
- ZBigArrays are the principal component of Wendelin, they are a wrapper around ndarrays for out-of-core persistence
- ndarrays are the numpy library's main datatype, and provide a reasonably performant interface for representing N-dimensional arrays of data
- A view is an interface to a ZBigArray or ndarray's data - a particular way to view the data
- The
getArray() method of Data Arrays returns the underlying ZBigArray
- ZBigArrays are usually manipulated through views to their underlying data
- A view is obtained by taking a slice of a ZBigArray or ndarray
- A ZBigArray view looks and acts just like an ndarray, and can be used wherever ndarrays are used
- It is important to note though that they are not normal ndarrays, and behave differently behind the scenes
More On Views
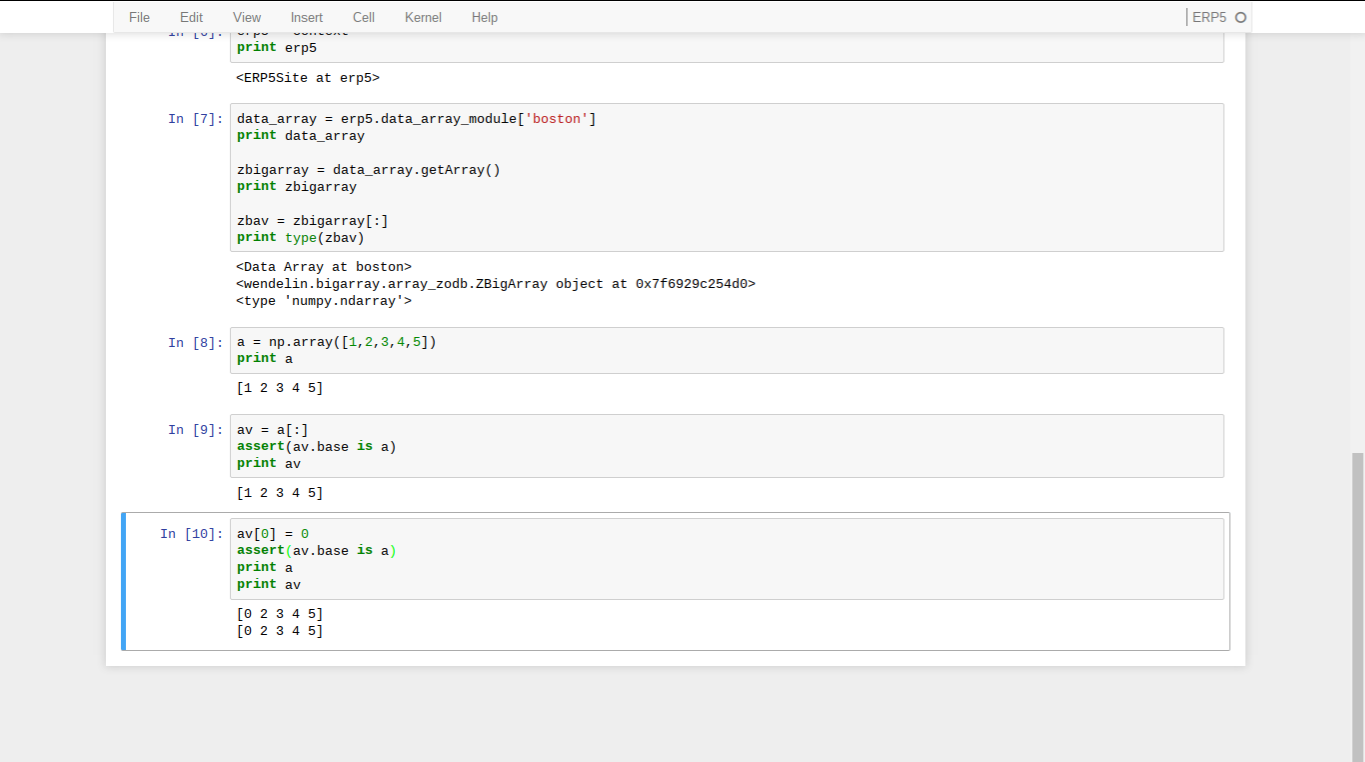
- You can think of a view as a pointer to an array's memory
- Changes you make to a view will also affect the array you are viewing
- It is therefore very important to keep track of which arrays are referenced by which views
- It can be helpful to give views names that specify it's a view as well as the array they reference
ZBigArrays - Reading is free
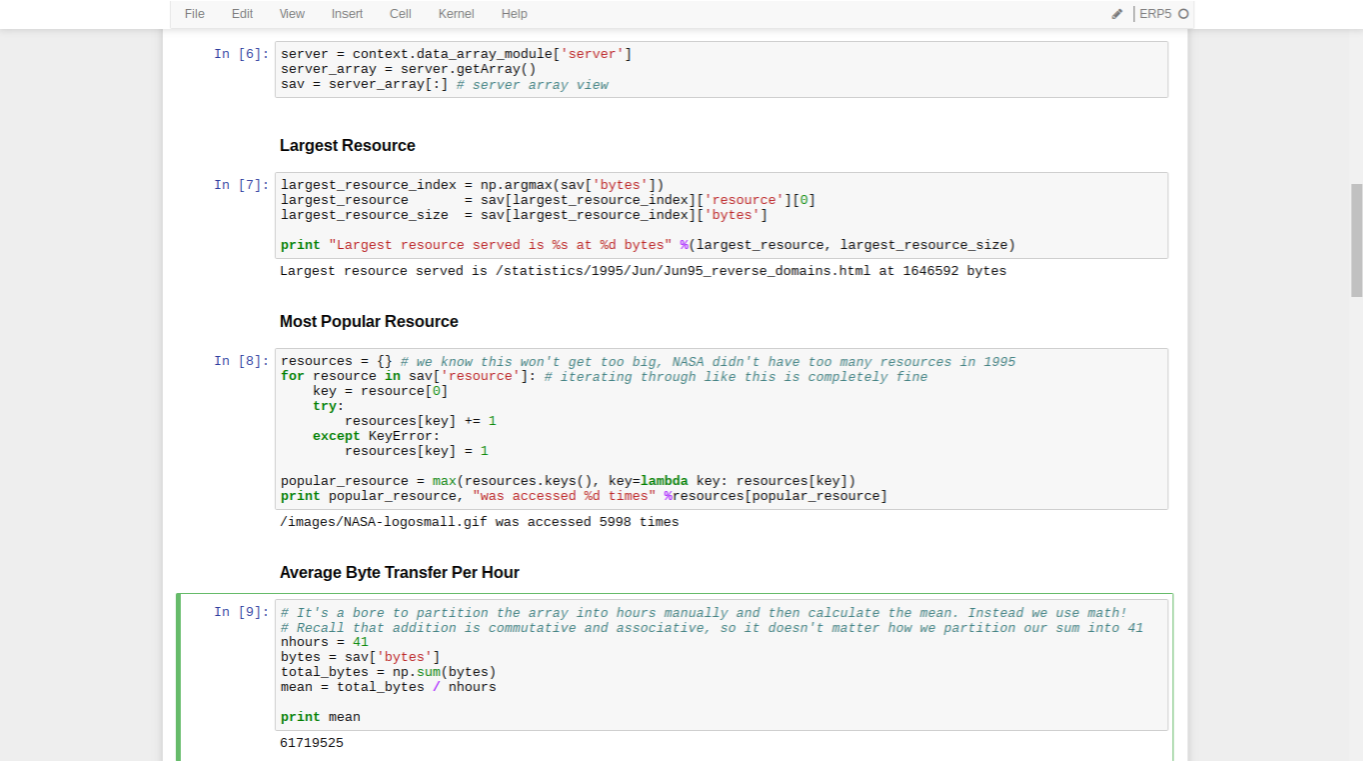
- A view can be taken into a ZBigArray that acts just like an ndarray -- except that you can read their data without loading the entire array into memory
- Functions like
numpy.max and numpy.sum that just read the array and return a number are completely safe
- Iterating through the array manually is also fine while you're not making modifications
- In these examples we use a ZBigArray array containing data from HTTP requests made to NASA's website in 1995
ZBigArrays - Writing is not free
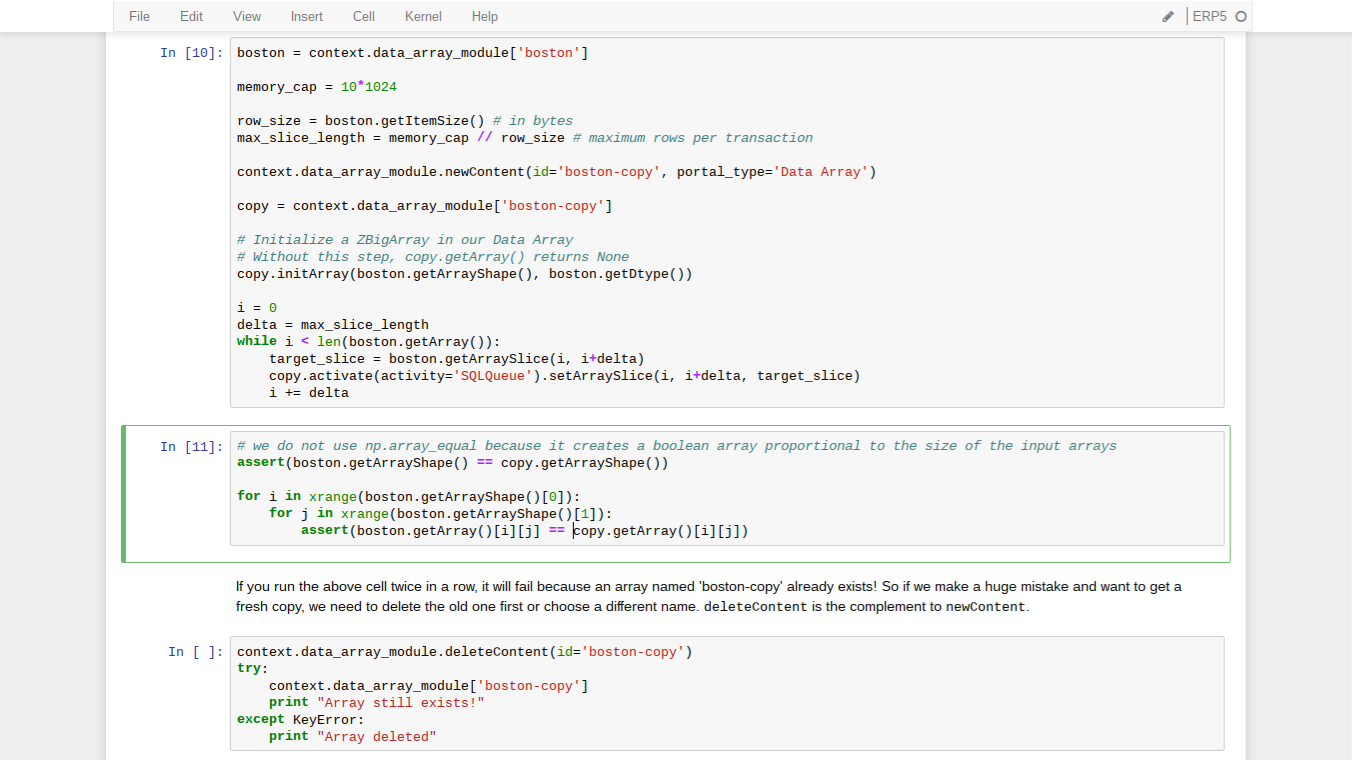
- ZBigArrays are modified transactionally
- Everytime you modify a ZBigArray, a transaction needs to occur for the change to persist
- Normally, a transaction occurs at the end of a Jupyter cell
- So if an entire bigger-than-memory array is modified in one transaction, more data than you have memory for needs to be loaded at once before being written to disk
- The solution is to hand chunks of modifications to an activity, which will perform them in separate transactions
- Transactions are aborted when an exception is raised
- As an aside, a process like this one can be easily automated with an ERP5 script or extension, read the developer or production tutorials for more
Machine Learning
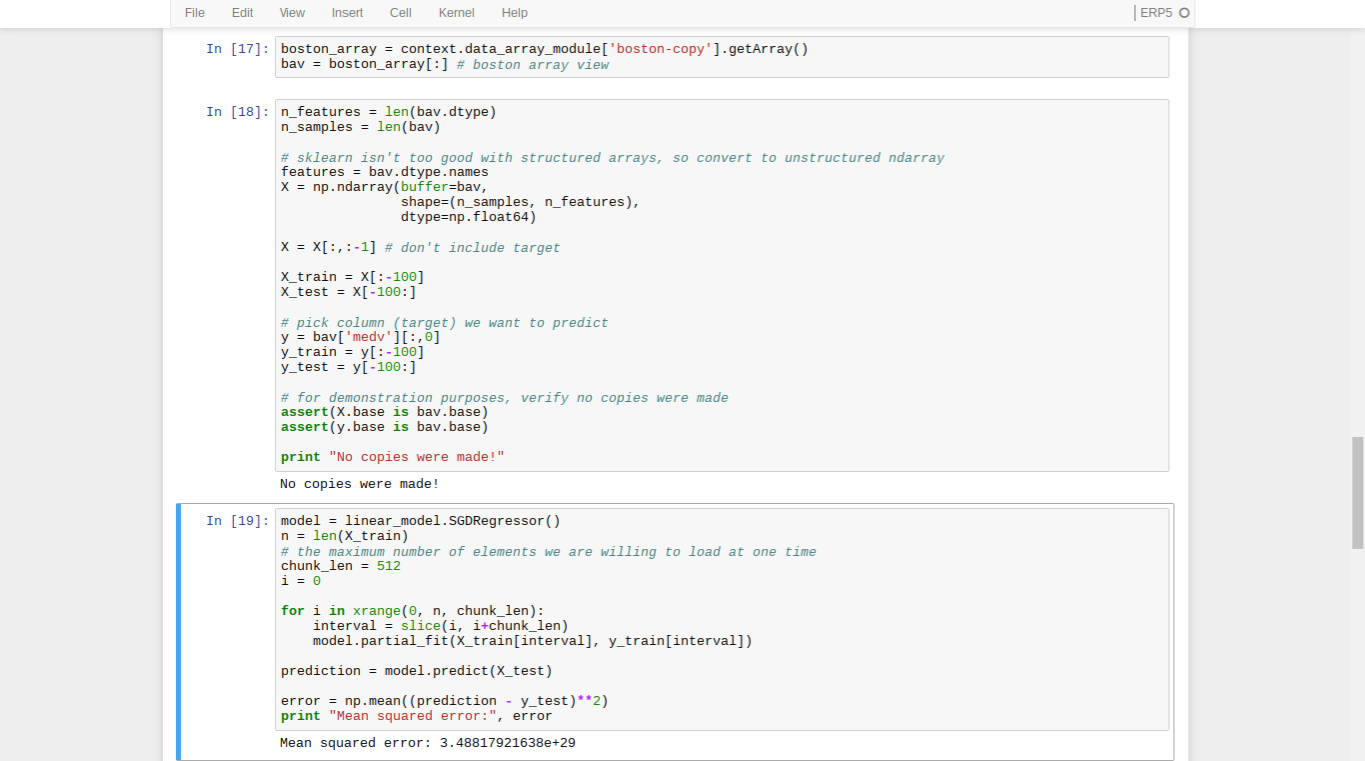
- Wendelin synergizes well with Scikit-Learn's incremental learning classes, like SGDRegressor
- We will begin by using all the features we have
- Using the same iterate-by-slices technique, we can feed our model data piecemeal
- Since our test data is small, there is no need to worry about memory otherwise
- We calculate the error rate by taking the mean of the square of the differences between the predicted values and the real values
- Your error rate will be different than the one in the screenshot, but of a similar magnitude
- Our error is massively high, which suggests something is wrong with our model
- All Scikit-learn classes that implement the
partial_fit method can be used for out-of-core learning
Plotting Data
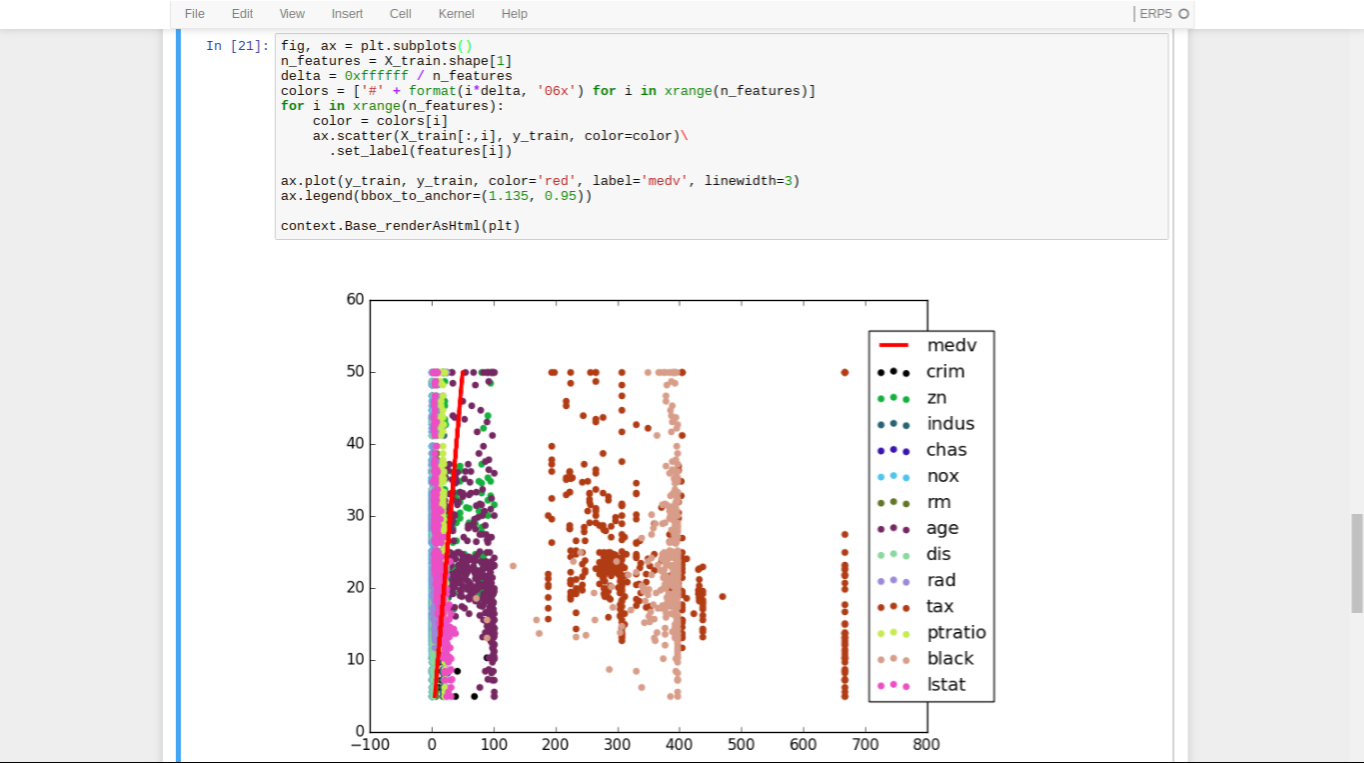
- It is often helpful to plot data during your analysis to better understand a problem
- The wide ranges our features take on may be the cause of the terrible prediction
- Our data would probably benefit from some preprocessing
- The only difference in plotting in the ERP5 kernel is that we use
context.Base_renderAsHtml(plt) instead of plt.show()
- Otherwise, you can do all the fancy things you are used to
Improving Our Model
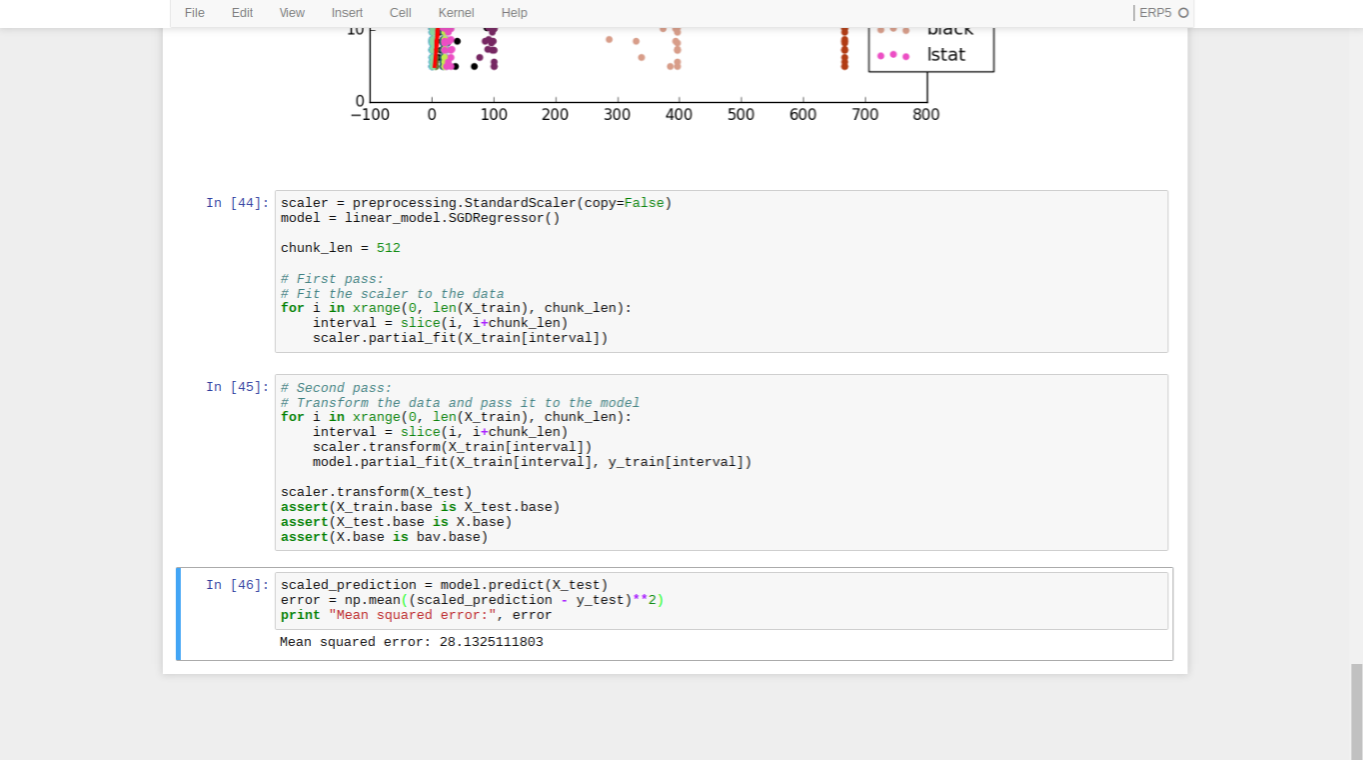
- The
StandardScaler class implements the partial_fit method, so we can use it with our big data
- We make a first pass to train our scaler, then a second pass to transform our data and pass it to the regressor
- Notice that we passed
copy=False to the StandardScaler constructor: we wouldn't want a bigger-than-memory array to be copied!
- This simple preprocessing reduces our error-rate by 28 orders of magnitude!
- To get a more accurate sense of our model's performance, you should use scikit-learn's model selection module to perform cross validation
Presenting Analysis
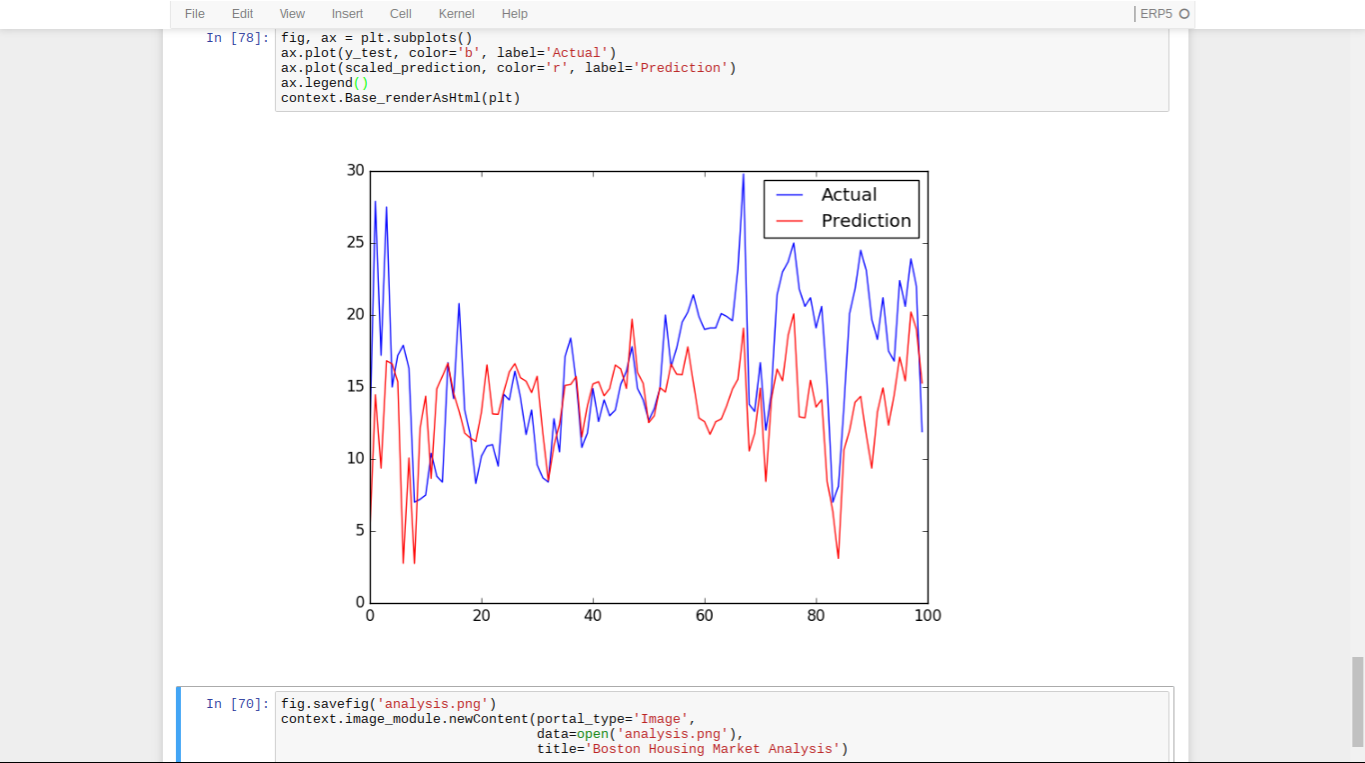
- We can plot our final prediction now and save it to ERP5 to present later
- You can access this object in ERP5 at
https://<YOUR_ERP5_URL>/erp5/image_module/1/
Presenting Analysis
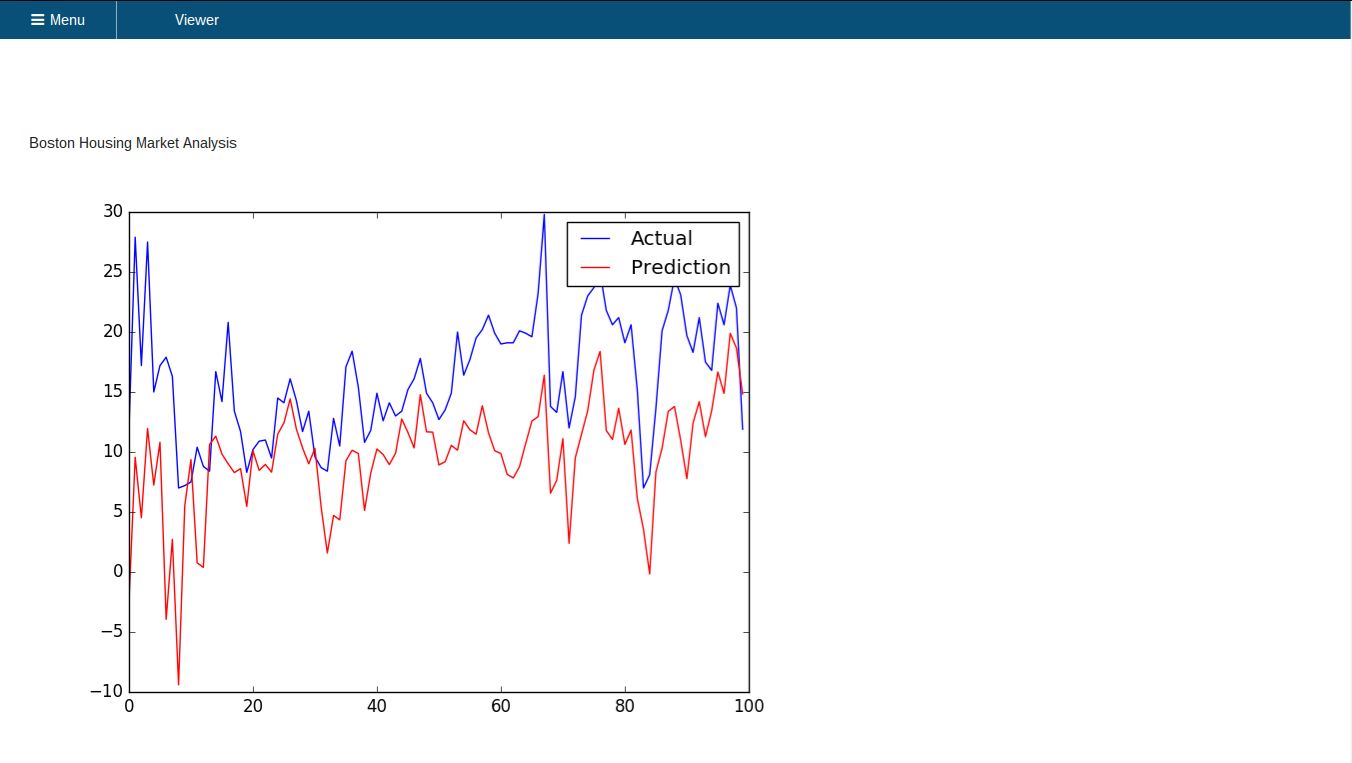
- ERP5 can also be used to host websites that present your graphs
- Such a site has already been set up
- Access it at
https://<YOUR_URL>/erp5/web_site_module/graph_visualizer/
- This app is written with RenderJS and jIO
- It can be extended through the web site and web page modules
Summary

After following this tutorial you should have learned:
- Out-of-core analysis refers to analyzing data that is larger than a single machine's RAM or hard disk
- ZBigArrays are manipulated with views, which look and act like normal ndarrays
- Techniques developed for out-of-core analysis work with Wendelin
- How to perform out-of-core machine learning with Wendelin
- That Wendelin can be used to present your analysis